
この「Python×EDINETによる財務分析と投資判断」のシリーズでは、EDINET(金融庁の電子開示システム)をPythonから活用することで、日本の上場企業の財務情報を収集・分析し、投資判断できるようになることを最終目標とする。
これは投資手法でいうと、ファンダメンタル投資にあたる。つまり、上場企業の決算書などから財務情報を取得し、収益性や財務安定性を定量的に評価することで投資先を決定する手法である。
本記事では、その手始めにEDINET APIからPythonを利用して財務情報を取得するところまでを解説する。今回取得する情報としては、書籍「わが投資術 (清原達郎)」の中で紹介されており、最近注目されているネットキャッシュという指標を採用した。
EDINET APIの利用方法
まずEDINET APIに関する基本的な説明や利用方法は、EDINETのページから、
「操作ガイド等」→「EDINET API仕様書 (Version2)」を閲覧していただきたい。併せて、利用規約等の確認もしていただき、これからの手順を実際に試す際には各自の責任のもとで行っていただきたい。
上記の仕様書のうち、第2章の手順に従ってEDINET APIを利用準備を行う。こちらの仕様書ではすべてのステップが画像付きで示されているため、そちらを参照していただくのが間違いない。2-1-1の手順では、Microsoft EdgeでEDINETのポップアップが許可されるように「https://api.edinet-fsa.go.jp/」をブロック対象外にする設定方法を示している。これを済ませたら、2-2-1の手順に従って、EDINET API アカウント作成からEDINET APIを利用するためのアカウントを作成する。ここで、氏名、メールアドレス、電話番号などを登録することで、APIキーが即座に発行されEDINET APIが利用可能になる。
APIキーはどこかに保存しておいて、以下で実際に利用する際に毎回コードに直書きしてもよいのだが、面倒なのとセキュリティの観点からもあまりよろしくはない。そこで、最も簡単な方法はWindowsの環境変数に登録してしまうことである。Windowsの設定から「環境変数」と検索すれば登録画面が出るので、以下のようにユーザー環境変数に登録しておく。

こうしておけば、あとでこのAPIキーを呼び出したいときは、変数名のEDINET_API_KEYと書けば値が代入される。以上で、EDINET APIに関する利用準備は終了である。Pythonなどと組み合わせれば、EDINETからデータを取得することが可能である。
Pythonを用いたEDINET APIの利用方法
それでは、ここから実際にPythonのコードを利用して、EDINETから財務情報を取得する流れを実践する。Pythonを利用する環境についてはこちらの記事で紹介した方法のうち、VScodeを用いた方法を採用し、ExtensionでJupyter Notebookを使用できるようにしている。私は普段、VimでPythonスクリプトを作成してまとめて解析することが多いが、今回はpandasを利用して順にデータを加工、取捨選択していくためJupyterとの相性がよいからである。また、今回用いたPythonはVer. 3.13.1である。
EDINET APIで必要な書類を取得
まずは日付を指定して、その期間に提出された書類をEDINETですべて検索する。JSON形式でデータベースが保存されているため、まずはそのままデータを持ってくることになる。実際のコードは以下の通りである。
import os
import requests
from datetime import datetime
from datetime import timedelta
import time
#dateで指定した日付に提出された財務書類をEDINETで探してJSON形式で返す関数
def get_edinet_documents(date):
url = "https://disclosure.edinet-fsa.go.jp/api/v2/documents.json"
params = {
"date": date,
"type": 2,
"Subscription-Key": os.environ.get("EDINET_API_KEY"), # for v2
}
res = requests.get(url, params=params)
return res.json()["results"]
#start_dataからend_dateまで、上記のget_edinet_documents関数を繰り返す
def get_documents_in_range(start_date, end_date):
all_docs = []
current_date = start_date
while current_date <= end_date:
print(f"Fetching: {current_date.strftime('%Y-%m-%d')}")
docs = get_edinet_documents(current_date.strftime("%Y-%m-%d"))
all_docs.extend(docs)
current_date += timedelta(days=1)
time.sleep(1)
return all_docs
#end_date = datetime.today() #本日を基準とする場合
end_date = datetime(2024, 11, 14)
start_date = end_date - timedelta(days=8)
all_docs = get_documents_in_range(start_date, end_date) #2024/11/6~11/14のデータを取得
all_docs今回は、最新の半期報告書のデータを狙って、2024/11/6~11/14に提出されたデータを取得した。これをall_docsという変数に保存しており、最後の行で出力しているので一部だけ次のように出力されるはずである。最初の「Fetching: …」という行は、実際に各日付でデータを取得しているときに、進捗を分かりやすくするために表示させた部分である。
Fetching: 2024-11-06
Fetching: 2024-11-07
Fetching: 2024-11-08
Fetching: 2024-11-09
Fetching: 2024-11-10
Fetching: 2024-11-11
Fetching: 2024-11-12
Fetching: 2024-11-13
Fetching: 2024-11-14
[{'seqNumber': 1,
'docID': 'S100UM44',
'edinetCode': 'E00945',
'secCode': '45280',
'JCN': '7120001077374',
'filerName': '小野薬品工業株式会社',
'fundCode': None,
'ordinanceCode': '010',
'formCode': '043A00',
'docTypeCode': '160',
'periodStart': '2024-04-01',
'periodEnd': '2025-03-31',
'submitDateTime': '2024-11-06 09:00',
'docDescription': '半期報告書-第77期(2024/04/01-2025/03/31)',
'issuerEdinetCode': None,
'subjectEdinetCode': None,
'subsidiaryEdinetCode': None,
'currentReportReason': None,
'parentDocID': None,
'opeDateTime': None,
'withdrawalStatus': '0',
'docInfoEditStatus': '0',
'disclosureStatus': '0',
'xbrlFlag': '1',
'pdfFlag': '1',
...
'attachDocFlag': '0',
'englishDocFlag': '0',
'csvFlag': '0',
'legalStatus': '1'},
...]まだ、JSON形式の生データのため見づらいが、例えば’secCode’は証券コード4桁と末尾に0を追加した5桁になっていたり、’filerName’はその書類を提出した企業名であったり、’docTypeCode’は書類の種類を表していたり、というように様々な情報を含んでいる。
これは一部しか表示されていないが、2024/11/6~11/14に提出されたデータすべての情報をすでに持っている。ここから、自分が気になる企業を探し出し、より詳しい財務情報を得るためにXBRLファイルを個別にダウンロードしていく。
東証の上場銘柄一覧から興味のある企業のコードを抽出
そこで、まずは自分の気になる企業をスクリーニングすることにする。今回は例として、農業関連の銘柄だけを選びだすことにしよう。ここだけはEDINET APIは関係ないが、東証が上場銘柄一覧をエクセルファイルでまとめているので、そこから情報を取得する。
import pandas as pd
# 東証の上場銘柄一覧Excelから証券コードを取得
url = "https://www.jpx.co.jp/markets/statistics-equities/misc/tvdivq0000001vg2-att/data_j.xls"
df = pd.read_excel(url)
agri_df = df[df["33業種区分"] == "水産・農林業"]
agri_df = agri_df[["コード", "銘柄名"]].copy()
agri_df["コード"] = agri_df["コード"].astype(str).str.zfill(4)+"0" #EDINETのデータと合わせるために末尾に0を追加して5桁とする
agri_df今回は例として農業関連の銘柄を見つけたかったので、このエクセルファイルの中の「33業種区分」という項目が「水産・農林業」となっているものの証券コードを取得した。また、先ほどEDINETから取得したデータを見たときに証券コードは末尾に0が追加されて5桁になっていたため、ここで取得した証券コードも合わせて5桁にしておいた。以下のように一覧が得られたはずである。
コード 銘柄名
0 13010 極洋
18 13320 ニッスイ
19 13330 マルハニチロ
39 13750 雪国まいたけ
40 13760 カネコ種苗
41 13770 サカタのタネ
42 13790 ホクト
44 13800 秋川牧園
45 13810 アクシーズ
46 13820 ホーブ
47 13830 ベルグアース
48 13840 ホクリヨウ銘柄コードで所望の企業のXBRLデータをzip形式でダウンロード
さて、今回情報を取り出したい企業の証券コードが得られたので、先ほどEDINET APIから取得しておいたデータの中で該当するものだけを残す。また、これらの企業のより詳しい財務情報を得るために、XBRLファイルの形式で保存されているデータをダウンロードする。このとき、サーバー負荷を低減させる目的で、各ファイルをダウンロードするごとに2秒間の待機時間を設けている。
import os
import time
os.makedirs("edinet_data", exist_ok=True) #XBRLデータの保存ディレクトリを作成
def download_xbrl(doc_id):
url = f"https://disclosure.edinet-fsa.go.jp/api/v2/documents/{doc_id}?type=1"
request_params = {
"Subscription-Key": os.environ.get("EDINET_API_KEY"),
}
res = requests.get(url, request_params)
#print(f"Response status: {res.status_code}") #for debug
#print(f"Response content: {res.content}") #for debug
with open(f"edinet_data/{doc_id}.zip", "wb") as f:
f.write(res.content)
# 提出書類から農業関連企業のものだけ抽出してダウンロード
agri_codes = agri_df["コード"].astype(str).values
for d in all_docs:
if d["secCode"] in agri_codes and d["docTypeCode"] in ["160"]: # docTypeCode=160 半期報告書, 120 有価証券報告書
print("Downloading... secCode="+d["secCode"])
time.sleep(2) #サーバー負荷を低減させるために2秒待機
download_xbrl(d["docID"])
print("Finished.")Downloading... secCode=13010
Downloading... secCode=13750
Downloading... secCode=13330
Downloading... secCode=13320
Downloading... secCode=13840
Downloading... secCode=13800
Downloading... secCode=13790
Finished.EDINETから取得したJSONに含まれていたdocTypeCodeは書類の種類を表すと説明したが、120であれば有価証券報告書、160であれば半期報告書に相当する。今回は半期報告書に着目するため160を指定した。ここで、実際にダウンロードした企業の数を見ると7つである。先ほど農業関連銘柄は12あったため、すべては取得できていない。これは今回最初に検索したデータの範囲が2024/11/6~11/14にしたことが原因である。農業関連銘柄の半期報告書の提出日を調べたところ以下の通りであった。
| 証券コード | 企業名 | 半期報告書の提出日 |
|---|---|---|
| 1301 | 極洋 | 2024/11/6 |
| 1332 | ニッスイ | 2024/11/13 |
| 1333 | マルハニチロ | 2024/11/12 |
| 1375 | 雪国まいたけ | 2024/11/8 |
| 1376 | カネコ種苗 | 2025/1/14 |
| 1377 | サカタのタネ | 2025/1/14 |
| 1379 | ホクト | 2024/11/14 |
| 1380 | 秋川牧園 | 2024/11/14 |
| 1381 | アクシーズ | 2025/2/7 |
| 1382 | ホーブ | 2025/2/13 |
| 1383 | ベルグアース | 2025/1/31 |
| 1384 | ホクリヨウ | 2024/11/13 |
決算期が企業によって異なるために、企業によって半期報告書の提出日も異なっている。今回はあらかじめこの情報をEDINETで調べており知っていたため、なるべく短い期間で多くの企業の情報を取得できるように2024/11/6~11/13の日付を選んでいたのである。
より効率的に情報を取得するためには、このデータ取得方法には工夫が必要であり、今後考えていく予定である。
XBRLをパースして必要な値を抽出
次はダウンロードしたXBRLファイルをPythonで処理していく。今回XBRLファイルをPythonで扱いやすい形に変えるように、データ構造を変換することをパース(Parse)するという。これに関しては、PythonでEdinetXbrlParserというものがあるので、それを利用する。そして、XBRLファイルの中に含まれる豊富な情報の中から、注目したい財務指標を抽出する。ここでは例として、以下で定義される少し単純化したネットキャッシュを取り出す。これの意味するところは、あとでグラフで結果を図示してから説明する。
(単純化した)ネットキャッシュ [円] = 流動資産の総額 ー 負債の総額
この計算に必要なデータを取得する際は、先ほどのEdinetXbrlParserを利用して、以下の関数で呼び出せる。
val = edinet_xbrl_object.get_data_by_context_ref(key, context_ref).get_value()ここで引数のkeyは要素名(先ほどの流動資産や負債など)であり、context_refはいつのデータか(今期か、1年前かなど)を指定する必要がある。これらの財務情報はすべてに要素名がつけられており、EDINETのタクソノミ一覧から調べる必要がある。keyとしては、今回の半期報告書から抽出する流動資産は”jppfs_cor:CurrentAssets”、負債は”jppfs_cor:Liabilities”という要素名がつけられている。また、context_refに関しては、今期なら”CurrentQuarterInstant”、1年前なら”Prior1YearInstant”を指定すればよい。以下は、実際にネットキャッシュの計算に必要なデータを取得する関数と、それをテストで証券コード1332のニッスイに対して適用したものである。
from edinet_xbrl.edinet_xbrl_parser import EdinetXbrlParser
import zipfile
import os
import pandas as pd
from bs4 import XMLParsedAsHTMLWarning
import warnings
warnings.filterwarnings("ignore", category=XMLParsedAsHTMLWarning) #parser_xbrlの中でXML parserでなくHTML parserを使っている警告が多数出るため
# Initialize parser
parser = EdinetXbrlParser()
# Open and parse XBRL file
def parse_xbrl(file_path):
print("Parsing... "+file_path)
with zipfile.ZipFile(file_path, 'r') as zf:
# PublicDocフォルダ内のXBRLファイルを特定
public_doc_folder = "XBRL/PublicDoc/"
xbrl_file_name = next(
(f for f in zf.namelist() if f.startswith(public_doc_folder) and f.endswith(".xbrl")),
None
)
if not xbrl_file_name:
raise ValueError("No XBRL file found in the PublicDoc folder.")
# XBRLファイルを一時的に解凍
extracted_path = f"./temp_{os.path.basename(xbrl_file_name)}"
with open(extracted_path, "wb") as xbrl_file:
xbrl_file.write(zf.read(xbrl_file_name))
# parserを使用してファイルを解析
edinet_xbrl_object = parser.parse_file(extracted_path)
# 一時ファイルを削除
os.remove(extracted_path)
key1_a = "jppfs_cor:CurrentAssets" # 流動資産
key1_b = "jpigp_cor:CurrentAssetsIFRS" # 流動資産
key2_a = "jppfs_cor:Liabilities" #負債
key2_b = "jpigp_cor:LiabilitiesIFRS" #負債
context_ref_a = "CurrentQuarterInstant" # 現在
context_ref_b = "CurrentQuarterInstant_NonConsolidatedMember" # 現在 (非連結会社)
try:
val1 = edinet_xbrl_object.get_data_by_context_ref(key1_a, context_ref_a).get_value()
val2 = edinet_xbrl_object.get_data_by_context_ref(key2_a, context_ref_a).get_value()
except:
try:
val1 = edinet_xbrl_object.get_data_by_context_ref(key1_b, context_ref_a).get_value()
val2 = edinet_xbrl_object.get_data_by_context_ref(key2_b, context_ref_a).get_value()
except:
try:
val1 = edinet_xbrl_object.get_data_by_context_ref(key1_a, context_ref_b).get_value()
val2 = edinet_xbrl_object.get_data_by_context_ref(key2_a, context_ref_b).get_value()
except:
try:
val1 = edinet_xbrl_object.get_data_by_context_ref(key1_b, context_ref_b).get_value()
val2 = edinet_xbrl_object.get_data_by_context_ref(key2_b, context_ref_b).get_value()
except:
print("cannot find the object in " + file_path)
return {
"流動資産": float(val1),
"負債": float(val2)
}
# 使用例
xbrl_file = "edinet_data/S100UKJ9.zip" #13320
x = parse_xbrl(xbrl_file)
print(x)Parsing... edinet_data/S100UKJ9.zip
{'流動資産': 341665000000.0, '負債': 357015000000.0}この結果から、ニッスイは流動資産が約3.42兆円、負債が約3.57兆円であり、単純化したネットキャッシュは約-150億円であるということが分かる。これは実際にEDINETからニッスイの半期報告書のB/Sを調べると、たしかにその通りであることが確かめられる。
また、このコードの中では、keyとcontext_refにバリエーションを持たせている。これは、少し条件が異なると要素名が変わってしまうのだが、現段階では細かいことにこだわらずになるべく情報を抜き出せるようにしたからである。ここも今後改善の余地がある。
ちなみに、XBRLファイルを探す際にPublicDoc/の中を探しているが、これは提出本文書が保管されているからである。もう1つのAuditDoc/は監査報告書のデータが保管されている。また、流動資産および負債を検索する際に、要素名の末尾にIFRSが含まれているものも許容した。これは、国際会計基準(IFRS)に基づいて作成された文書であることを示している。会計基準による違いにも注意が必要であるが、今回はどちらも区別せずにデータ収集することとした。
ネットキャッシュを計算・可視化
先ほど定義した関数で特定の企業のXBRLファイルから流動資産や負債を取り出すことができるようになったので、最後にダウンロード済みの農業関連のXBRLファイルをすべて処理していく。その結果、すべての企業(のうち流動資産と負債の情報があるもの)のネットキャッシュが計算できるため、最後にPythonのmatplotlibを用いてグラフ化した。
import matplotlib.pyplot as plt
results = []
for d in all_docs:
code = d["secCode"]
name = d["filerName"]
if code in agri_codes:
try:
xbrl_file = f"edinet_data/{d['docID']}.zip"
print("secCode="+code)
x = parse_xbrl(xbrl_file)
simple_net_cash = x["流動資産"] - x["負債"]
results.append({"コード": code, "会社名": name, "ネットキャッシュ": simple_net_cash})
except:
continue
df_result = pd.DataFrame(results).sort_values("ネットキャッシュ", ascending=False)
# グラフ表示
plt.figure(figsize=(10, 6))
plt.barh(df_result["コード"], df_result["ネットキャッシュ"]/1000000000)
plt.xlabel("Simple Net Cash [billion yen]")
plt.ylabel("secCode")
plt.title("Simple Net Cash of Agriculture")
plt.tight_layout()
plt.show()secCode=13010
Parsing... edinet_data/S100UMRV.zip
secCode=13010
Parsing... edinet_data/S100UN64.zip
secCode=13750
Parsing... edinet_data/S100UO89.zip
secCode=13750
Parsing... edinet_data/S100UOCA.zip
secCode=13330
Parsing... edinet_data/S100UP65.zip
secCode=13330
Parsing... edinet_data/S100UP6A.zip
secCode=13320
Parsing... edinet_data/S100UKJ9.zip
secCode=13320
Parsing... edinet_data/S100UQDM.zip
secCode=13840
Parsing... edinet_data/S100UQDP.zip
secCode=13840
Parsing... edinet_data/S100UQDR.zip
secCode=13800
Parsing... edinet_data/S100US1O.zip
secCode=13800
Parsing... edinet_data/S100US1S.zip
secCode=13790
Parsing... edinet_data/S100URT6.zip
secCode=13790
Parsing... edinet_data/S100URTE.zip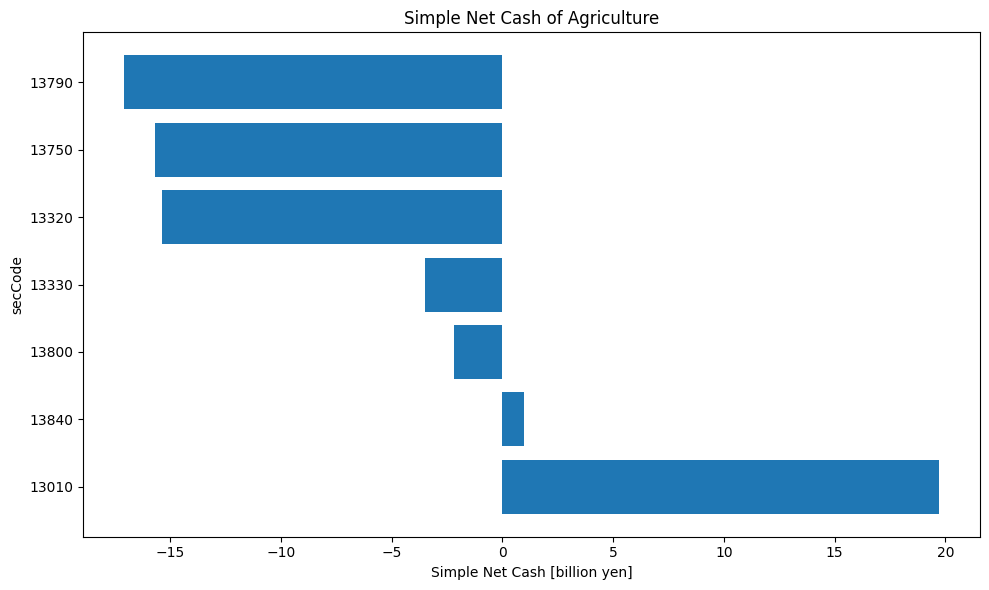
縦軸に証券コードを並べ、それぞれのネットキャッシュを横軸に10億円単位で図示した。まず半期報告書を取得できた7つの企業すべてでネットキャッシュを計算できていることが分かる。そして、実際に得られた結果を見ると、ネットキャッシュがプラスになっているのは、証券コード1384のホクリヨウと1301の極洋の2つだけであることが分かる。ここまでで、本記事での目標は達成された。
ネットキャッシュとは
最後に、得られたネットキャッシュとは何を意味するのかを説明する。
ネットキャッシュとは、簡単に言えば借金を返済したあとに企業の手元に残る現金であり、財務の健全性を表す指標となる。正しくは以下のように定義される:
ネットキャッシュ [円] = 流動資産の総額 + (0.7×投資有価証券の総額) ー 負債の総額
流動資産とは1年以内に現金化できる資産のことであり、手元にある現金と考えてもよいだろう。また、負債は借金のことであるから、すべて清算して残る金額が実質的に企業が持っているお金と考えられる。このように(単純化した)ネットキャッシュとは非常にシンプルな考え方である。さらに、投資有価証券とは固定資産の中に含まれる満期目的で保有する証券であるが、これも現金化は可能なので税金の差し引き分でざっと0.7掛けでプラスしたのがネットキャッシュの本来の定義である。
今回はXBRLデータからの取得において安定性の観点から、(単純化した)ネットキャッシュを用いて投資有価証券については無視した。
このことを踏まえて最後に得られた結果を見ると、ネットキャッシュがプラスであった2つの企業は借金をすぐに返済しても手元にお金が残るだけの余裕があることが分かる。つまり、ただちに借金を返せなくなって倒産するといったことは起きにくいだろうと考えられる。あとは、これらの企業の時価総額と比べると、このインパクトはどれくらいであるかを考えたり、今後余剰資金をどのように活用していく予定なのかを個別に調べたり、という具合に詳しく検討していけばよい。
まとめ
以上、EDINET APIからPythonを利用して財務情報を抽出することができた。今回は使い方の説明であったため、この結果から具体的な投資判断まではできないが、今後効果的な指標を考え出せばこの手法で自動スクリーニングが可能になるはずである。
しかし、今回紹介した方法の中にもまだまだ改善点が多い。
まずEDINET APIは非常に強力だが、提出書類の取得にはいくつかの制約がある。例えば、取得クエリは提出日ベースで行う必要があり、銘柄コードや業種などで事前にフィルタリングすることはできない。このため、たとえ農業関連など特定の銘柄に注目したい場合でも、先に日付ベースで全件を取得し、その後に銘柄を取捨選択するという手順が必須となる。その他にも、情報が不完全な企業がある、XBRLの構造が企業や年度により異なるなど、課題も多い。
また、APIの仕様上、一度に膨大なデータを取得するのはマナー違反とされる可能性があるため、例えば直近1週間分のみを対象にするなど、段階的なダウンロードが望ましい。
今後は、上記の改善と、より包括的な財務指標(売上、営業CF、投資有価証券など)や、業種別の定量比較なども視野に入れ、活用の幅を広げていきたい。最終的には投資判断できるレベルまで到達することを目指したい。


コメント